Predicting real names while blocking fake names
I was on a forum recently where I noticed several of the posts were moderators informing new users that they were violating the site’s rules by not using a real name. The rules require users to use a real name or at least something “name-like” in order to participate in the community. I started wondering if it would be possible to design a system that could predict name validity. A simple solution would be to run the name through a database of known names, but new names are constantly being creating, making this method fairly short-sighted. Better would be to train a system with sample names and then give a provided name a score that assesses its validity. To accomplish this, I needed three sets of data:
- A list of real names to train the system
- A list of real names to test the system
- A list of fake names to test the system
Sets one and two were easy to come by. The SSA maintains a database of all birth names that can be downloaded and easily parsed. I found the top 1000 names to be not quite a good enough training set. 10000 was unnecessarily long and 5000 seemed to be about right. Set two is just a random sampling of names based on the frequency provided in the dataset. For my third set, I searched pastebin and found a list of about 750 Youtube usernames (I removed non word characters from this list). There are probably dozens of approaches one could take to train the system, but I decided to use letter clustering. I wanted to see which three-letter clusters were most common in names. For example, the name “Timothy” beaks down into TIM, IMO, MOT, OTH, and THY. I ran through the list of training names and counted the frequencies of each possible combination. As it turned out, further training by including word breaks helped a lot. So I did another pass of the data and included “*” as a name-break character. There are 51342 possible clusters when including the name breaks, but interesting only 2.67% of the clusters show up at all in the top 5000 names. The top clusters were RIS, ANN, *MAR, ARI, and AND. Next came the interesting part. I passed each set of test data through the same system to generate the clusters in the names of the test data. I summed the frequency counts of each cluster and divided by the number of characters in the name to normalize the score. Here’s a comparison of the score densities of the two sets:
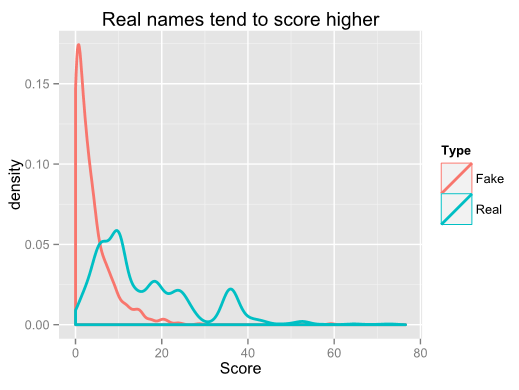
I was pretty happy with these results. With no refinements other than accounting for name breaks, the median real name score was 7.33 points higher than the median fake name score. Assigning a “tolerance level” would be up to the site owner. Setting the tolerance too high would result in annoying a lot of people using a real name with a low score, while setting the tolerance too low would allow too many fake users. Using a tolerance of 6.0, this method would flag ~22% of real-name users and allow ~22% of fake name users to pass by without a flag. So what improvements could be made? 1. Short real names still get too low of scores even when normalizing the scores. For example, the names “ADAM” and “JUAN” both only get a score of 1.0.
- Some fake names are still “name-like” and therefore will pass by easily. Consider “CHARLIEIZE” and “CODEYBRISTOL” with scores of 28.7 and 17.75 respectively.
- It will undoubtedly fail miserably for real names in languages other than English.
However, I think this proves the proof of concept and would be fairly simple to implement as a second step in the name verification process. There were only approximately 22,000 unique names in my SSA dataset. Comparing the new user’s chosen name through a database of that size is fairly trivial. If a match is found, the name would be validated. If not, a probability method such as this could be implemented to detect the validity of the name.