Parallel File Reading: Python vs Java
Given a set of files, I wanted to see how Python and Java would perform in both single- and multi- threaded environments. As a simple task, I chose to just count up the number of bytes in a given file by manually iterating over the bytes. Essentially–an intentionally non-optimal method of calculating the file size. Java is usually faster than Python, but I was surprised to see that for this task, Python significantly faster.
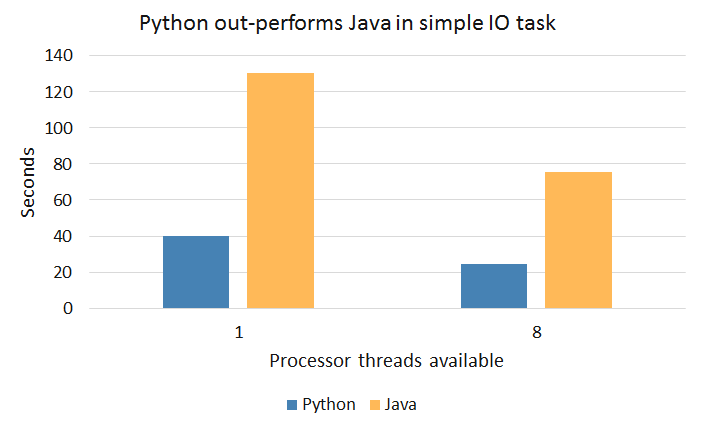
My test for this was to read approximately 185MB worth of data spread across 18 files on my 2012 MacBook Pro Intel i7 (2.9GHz). Both programs performed approximately 40% better when utilizing multiple threads and Python was overall about 70% faster. In Java, we can use a SimpleFileVisitor to walk the directory tree, and ask an ExecutorService to execute a list of Callables.
import java.util.concurrent.*;
import java.util.List;
import java.util.ArrayList;
import java.io.IOException;
import java.io.File;
import java.io.FileReader;
import java.io.FileInputStream;
import java.nio.file.*;
import java.nio.file.attribute.BasicFileAttributes;
public class FileProc {
public static void main(String[] args) throws Exception {
List<FileProcessor> todo = new ArrayList<>();
Path rootDir = Paths.get("/Users/phillip/Dropbox/eBooks");
Files.walkFileTree(rootDir, new SimpleFileVisitor<Path>() {
@Override
public FileVisitResult visitFile(Path path, BasicFileAttributes attr)
throws IOException {
String location = path.toString();
todo.add(new FileProcessor(new File(location)));
return FileVisitResult.CONTINUE;
}
});
//Choose one:
//ExecutorService executor = Executors.newSingleThreadExecutor();
//ExecutorService executor = Executors.newFixedThreadPool(8);
List<Future<FileDetails>> futures = executor.invokeAll(todo);
for(Future<FileDetails> future : futures) {
System.out.println(future.get());
}
executor.shutdown();
}
}
class FileProcessor implements Callable<FileDetails> {
private File file;
public FileProcessor(File file){
this.file = file;
}
public FileDetails call() throws IOException {
String fileName = file.getName();
Path path = Paths.get(file.getPath());
int fileSize = getSizeManually();
return new FileDetails(fileName, fileSize);
}
private int getSizeManually() throws IOException {
int sum = 0;
try(FileInputStream fis = new FileInputStream(file)) {
while(fis.read() != -1){
sum++;
}
}
return sum;
}
}
class FileDetails {
private String fileName;
private int fileSize;
public FileDetails(String fileName, int fileSize) {
this.fileName = fileName;
this.fileSize = fileSize;
}
@Override
public String toString(){
return fileName + " .... " + fileSize + " bytes";
}
}
In Python, the code is much more concise. We use os.walk to walk the directory tree and map a function to a (thread) Pool:
from multiprocessing import Pool
import os
def main():
with Pool(processes=8) as pool:
print(pool.map(process_file, get_files()))
def get_files():
files = []
root = "/Users/phillip/Dropbox/eBooks"
for (dirpath, dirnames, filenames) in os.walk(root):
for f in filenames:
files.append(dirpath + "/" + f)
return files
def process_file(file):
with open(file,'rb') as to_process:
sum = 0
byte = to_process.read(1)
while byte:
byte = to_process.read(1)
sum += 1
return {"fileName":to_process.name,"fileSize":sum}
if __name__=="__main__":
main()
I don’t know much about the Python internals, so let me know if you have any insight as to why it was so much faster than the Java code!